本文共 32928 字,大约阅读时间需要 109 分钟。
什么是logback
logback 用于日志记录,可以将日志输出到控制台、文件、数据库和邮件等,相比其它所有的日志系统,logback 更快并且更小,包含了许多独特并且有用的特性。
logback 被分成三个不同的模块:logback-core,logback-classic,logback-access。
- logback-core 是其它两个模块的基础。
- logback-classic 模块可以看作是 log4j 的一个优化版本,它天然的支持 SLF4J。
- logback-access 提供了 http 访问日志的功能,可以与 Servlet 容器进行整合,例如:Tomcat、Jetty。
本文将介绍以下内容,由于篇幅较长,可根据需要选择阅读:
-
如何使用 logback:将日志输出到控制台、文件和数据库,以及使用 JMX 配置 logback;
-
logback 配置文件详解;
-
logback 的源码分析。
如何使用logback
需求
- 使用 logback 将日志信息分别输出到控制台、文件、数据库。
- 使用 JMX 方式配置 logback。
工程环境
JDK:1.8.0_231
maven:3.6.1 IDE:Spring Tool Suite 4.3.2.RELEASE mysql:5.7.28主要步骤
- 搭建环境;
- 配置 logback 文件;
- 编写代码:获取
Logger实例,并打印指定等级的日志; - 测试。
创建项目
项目类型 Maven Project ,打包方式 jar。
引入依赖
logack 天然的支持 slf4j,不需要像其他日志框架一样引入适配层(如 log4j 需引入 slf4j-log4j12 )。通过后面的源码分析可知,logback 只是将适配相关代码放入了 logback-classic。
junit junit 4.12 test org.slf4j slf4j-api 1.7.28 jar compile ch.qos.logback logback-core 1.2.3 jar ch.qos.logback logback-classic 1.2.3 jar mysql mysql-connector-java 8.0.17 com.mchange c3p0 0.9.5.4
将日志输出到控制台
配置文件
配置文件放在 resources 下,文件名可以为 logback-test.xml 或 logback.xml,实际项目中可以考虑在测试环境中使用 logback-test.xml ,在生产环境中使用 logback.xml( 当然 logback 还支持使用 groovy 文件或 SPI 机制进行配置,本文暂不涉及)。
在 logback中,logger 可以看成为我们输出日志的对象,而这个对象打印日志时必须遵循 appender 中定义的输出格式和输出目的地等。注意,root logger 是一个特殊的 logger。
%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{50} - %msg%n
另外,即使我们没有配置,logback 也会默认产生一个 root logger ,并为它配置一个 ConsoleAppender。
编写测试类
为了程序的解耦,一般我们在使用日志时会采用门面模式,即通过 slf4j 或 commons-logging 来获取 Logger 对象。
以下代码中,导入的两个类 Logger 、 LoggerFactory都定义在 slf4j-api 中,完全不会涉及到 logback 包的类。这时,如果我们想切换 log4j 作为日志支持,只要修改 pom.xml 和日志配置文件就行,项目代码并不需要改动。源码分析部分将分析 slf4j 如何实现门面模式。
@Test public void test01() { Logger logger = LoggerFactory.getLogger(LogbackTest.class); logger.debug("输出DEBUG级别日志"); logger.info("输出INFO级别日志"); logger.warn("输出WARN级别日志"); logger.error("输出ERROR级别日志"); } 注意,这里获取的 logger 不是我们配置的 root logger,而是以 cn.zzs.logback.LogbackTest 命名的 logger,它继承了祖先 root logger 的配置。
测试
运行测试方法,可以看到在控制台打印如下信息:
2020-01-16 09:10:40 [main] INFO ROOT - 输出INFO级别的日志2020-01-16 09:10:40 [main] WARN ROOT - 输出WARN级别的日志2020-01-16 09:10:40 [main] ERROR ROOT - 输出ERROR级别的日志
这时我们会发现,怎么没有 debug 级别的日志?因为我们配置了日志等级为 info,小于 info 等级的日志不会被打印出来。日志等级如下:
ALL < TRACE < DEBUG < INFO < WARN < ERROR < OFF
将日志输出到滚动文件
本例子将在以上例子基础上修改。测试方法代码不需要修改,只要修改配置文件就可以了。
配置文件
前面已经讲过,appender 中定义日志的输出格式和输出目的地等,所以,要将日志输出到滚动文件,只要修改appender 就行。logback 提供了RollingFileAppender来支持打印日志到滚动文件。
以下配置中,设置了文件大小超过100M后会按指定命名格式生成新的日志文件。
${LOG_HOME}/${APP_NAME}/error.log true ERROR ACCEPT DENY ${LOG_HOME}/${APP_NAME}/notError-%d{yyyy-MM-dd}-%i.log 50 100MB 20GB %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
测试
运行测试方法,我们可以在指定目录看到生成的日志文件。
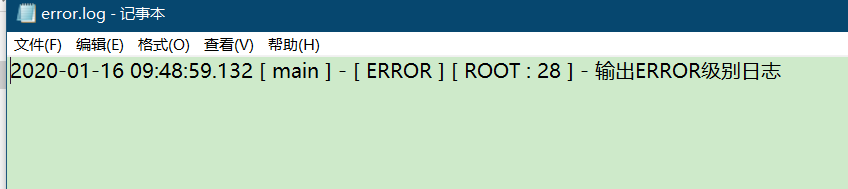
查看日志文件,可以看到只打印了 error 等级的日志:
将日志输出到数据库
logback 提供了DBAppender来支持将日志输出到数据库中。
创建表
logback 为我们提供了三张表用于记录日志, 在使用DBAppender之前,这三张表必须存在。
这三张表分别为:logging_event, logging_event_property 与 logging_event_exception。logback 自带 SQL 脚本来创建表,这些脚本在 logback-classic/src/main/java/ch/qos/logback/classic/db/script 文件夹下,相关脚本也可以再本项目的 resources/script 找到。
由于本文使用的是 mysql 数据库,执行以下脚本(注意,官方给的 sql 中部分字段设置了NOT NULL 的约束,可能存在插入报错的情况,可以考虑调整):
BEGIN;DROP TABLE IF EXISTS logging_event_property;DROP TABLE IF EXISTS logging_event_exception;DROP TABLE IF EXISTS logging_event;COMMIT;BEGIN;CREATE TABLE logging_event ( timestmp BIGINT NOT NULL, formatted_message TEXT NOT NULL, logger_name VARCHAR(254) NOT NULL, level_string VARCHAR(254) NOT NULL, thread_name VARCHAR(254), reference_flag SMALLINT, arg0 VARCHAR(254), arg1 VARCHAR(254), arg2 VARCHAR(254), arg3 VARCHAR(254), caller_filename VARCHAR(254), caller_class VARCHAR(254) NOT NULL, caller_method VARCHAR(254) NOT NULL, caller_line CHAR(4) NOT NULL, event_id BIGINT NOT NULL AUTO_INCREMENT PRIMARY KEY );COMMIT;BEGIN;CREATE TABLE logging_event_property ( event_id BIGINT NOT NULL, mapped_key VARCHAR(254) NOT NULL, mapped_value TEXT, PRIMARY KEY(event_id, mapped_key), FOREIGN KEY (event_id) REFERENCES logging_event(event_id) );COMMIT;BEGIN;CREATE TABLE logging_event_exception ( event_id BIGINT NOT NULL, i SMALLINT NOT NULL, trace_line VARCHAR(254) NOT NULL, PRIMARY KEY(event_id, i), FOREIGN KEY (event_id) REFERENCES logging_event(event_id) );COMMIT;
可以看到生成了三个表:

配置文件
logback 支持使用 DataSourceConnectionSource,DriverManagerConnectionSource 与 JNDIConnectionSource 三种方式配置数据源 。本文选择第一种,并使用以 c3p0 作为数据源(第二种方式文中也会给出)。
这里需要说明下,因为实例化 c3p0 的数据源对象ComboPooledDataSource时,会去自动加载 classpath 下名为 c3p0-config.xml 的配置文件,所以,我们不需要再去指定 dataSource 节点下的参数,如果是 druid 或 dbcp 等则需要指定。
测试
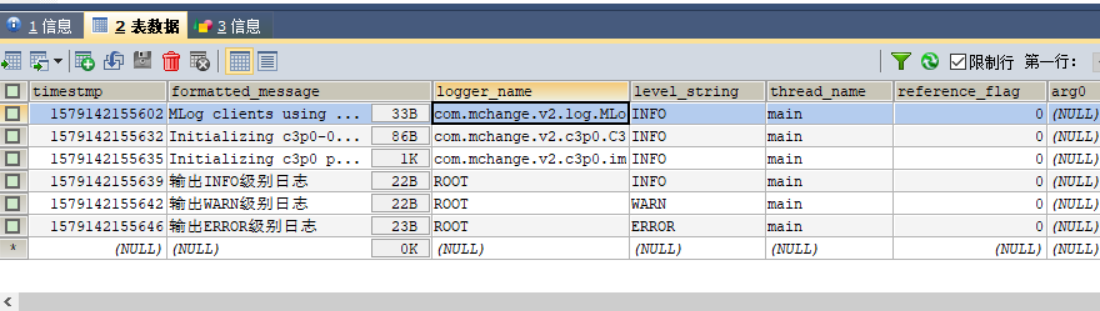
运行测试方法,可以看到数据库中插入了以下数据:
使用JMX配置logback
logback 支持使用 JMX 动态地更新配置。开启 JMX 非常简单,只需要增加 jmxConfigurator 节点就可以了,如下:
system.err ${LOG_PATTERN}
在我们通过 jconsole 连接到服务器上之后(jconsole 在 JDK 安装目录的 bin 目录下),在 MBeans 面板上,在 “ch.qos.logback.classic.jmx.Configurator” 文件夹下你可以看到几个选项。如下图所示:
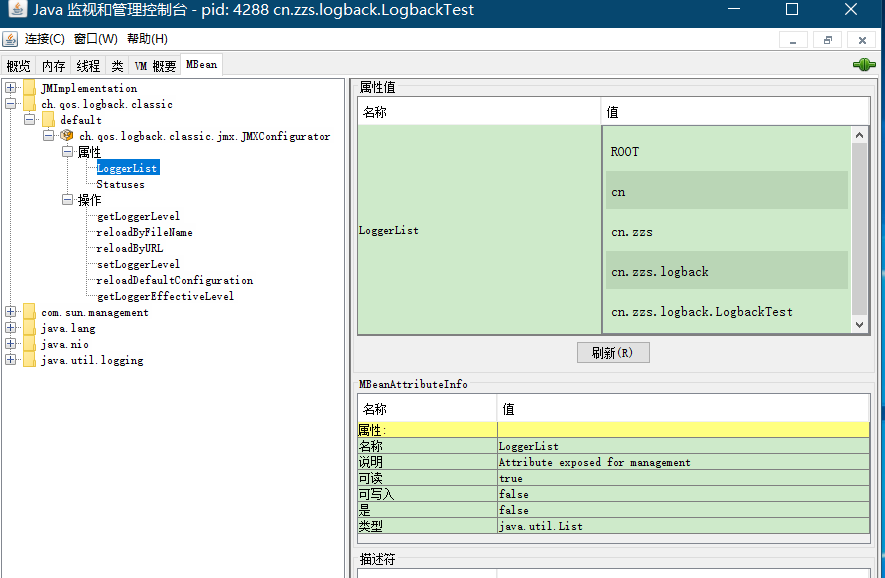
我们可以看到,在属性中,我们可以查看 logback 已经产生的 logger 和 logback 的内部状态,通过操作,我们可以:
- 获取指定 logger 的级别。返回值可以为 null
- 设置指定的 logger 的级别。想要设置为 null,传递 “null” 字符串就可以
- 通过指定的文件重新加载配置
- 通过指定的 URL 重新加载配置
- 使用默认配置文件重新加载 logback 的配置
- 或者指定 logger 的有效级别
更多 JMX 相关内容可参考我的另一篇博客:
补充–两种打印方式
实际项目中,有时我们需要对打印的内容进行一定处理,如下:
logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i])); 这种情况会产生构建消息参数的成本,为了避免以上损耗,可以修改如下:
if(logger.isDebugEnabled()) { logger.debug("Entry number: " + i + " is " + String.valueOf(entry[i]));} 当我们打印的是一个对象时,也可以采用以下方法来优化:
// 不推荐logger.debug("The new entry is " + entry + ".");// 推荐logger.debug("The new entry is {}", entry); 配置文件详解
前面已经说过, logback 配置文件名可以为 logback-test.xml 、 logback.groovy 或 logback.xml ,除了采用配置文件方式, logback 也支持使用 SPI 机制加载 ch.qos.logback.classic.spi.Configurator 的实现类来进行配置。以下讲解仅针对 xml 格式文件的配置方式展开。
另外,如果想要自定义配置文件的名字,可以通过系统属性指定:
-Dlogging.config=classpath:logback-sit.xml
如果没有加载到配置,logback 会调用 BasicConfigurator 进行默认的配置。
configuration
configuration 是 logback.xml 或 logback-test.xml 文件的根节点。
configuration 主要用于配置某些全局的日志行为,常见的配置参数如下:
| 属性名 | 描述 |
|---|---|
| debug | 是否打印 logback 的内部状态,开启有利于排查 logback 的异常。默认 false |
| scan | 是否在运行时扫描配置文件是否更新,如果更新时则重新解析并更新配置。如果更改后的配置文件有语法错误,则会回退到之前的配置文件。默认 false |
| scanPeriod | 多久扫描一次配置文件是否修改,单位可以是毫秒、秒、分钟或者小时。默认情况下,一分钟扫描一次配置文件。 |
配置方式如下:
system.err %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
使用以上配置进行测试:
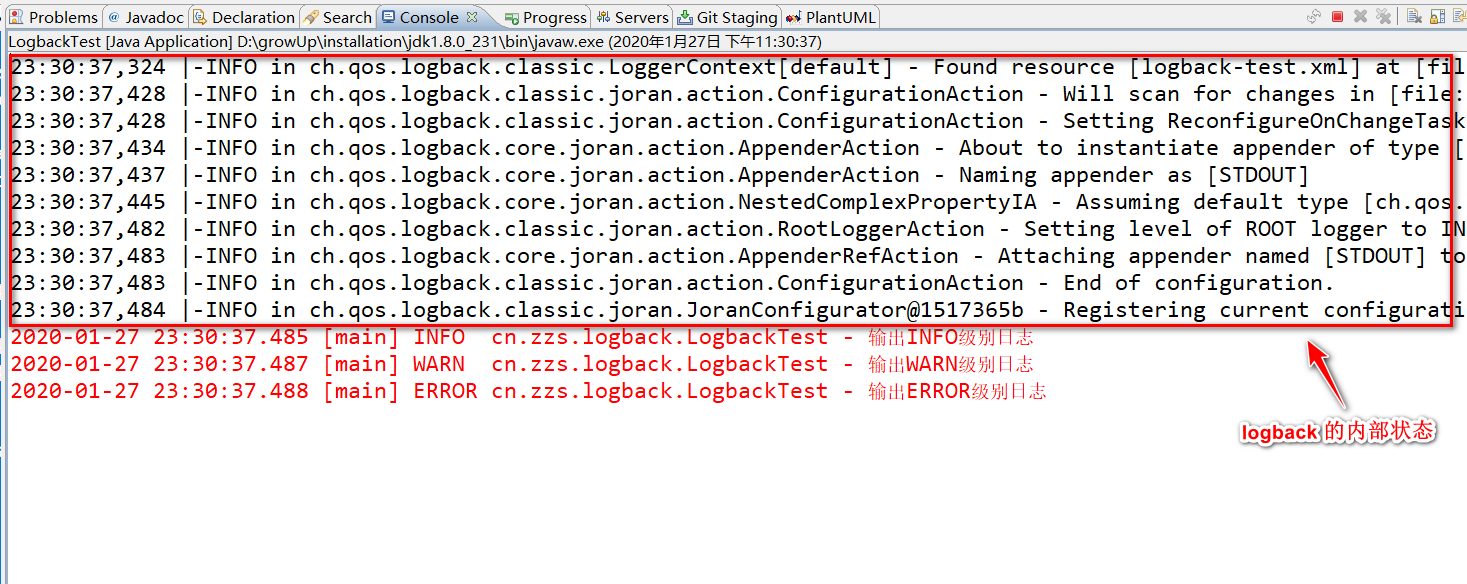
如上图,通过控制台我们可以查看 logback 加载配置的过程,这时,我们尝试修改 logback 配置文件的内容:
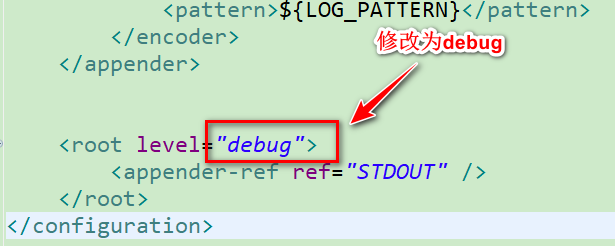
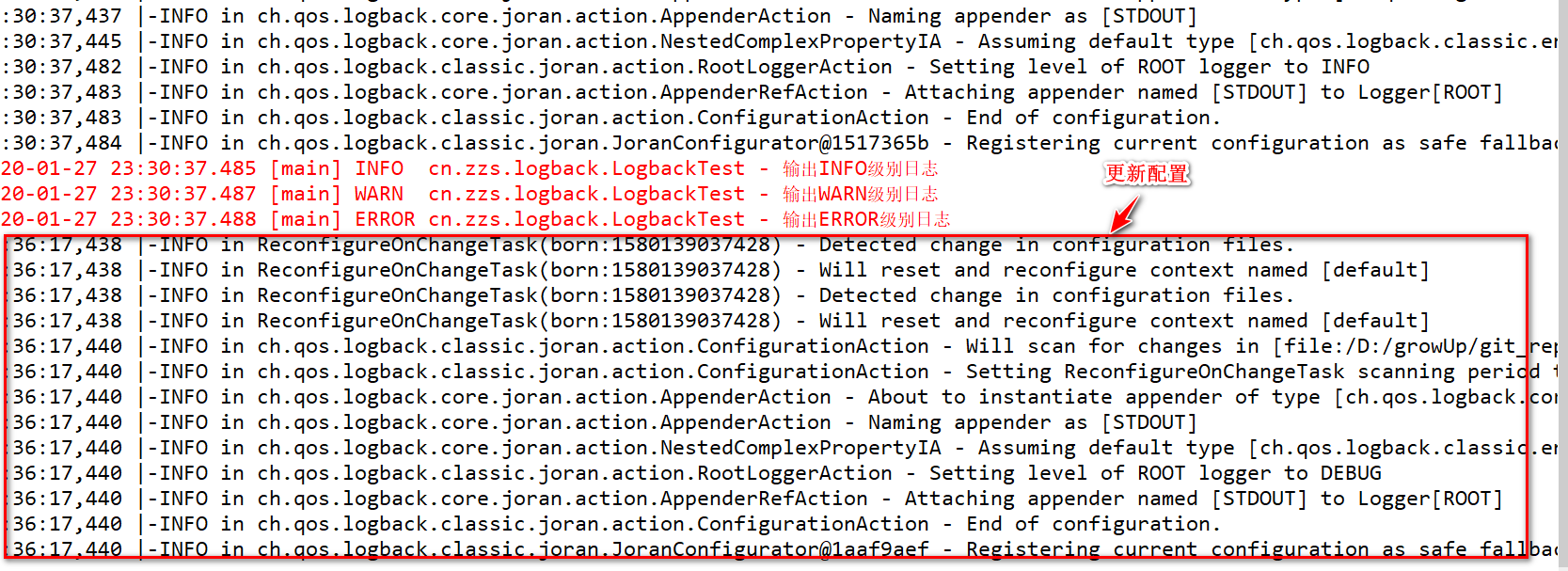
观察控制台,可以看到配置文件重新加载:
logger
前面提到过,logger 是为我们打印日志的对象,这个概念非常重要,有助于更好地理解 logger 的继承关系。
在以下代码中,我们可以在getLogger方法中传入的是当前类的 Class 对象或全限定类名,本质上获取到的都是一个 logger 对象(如果该 logger 不存在,才会创建)。
@Test public void test01() { Logger logger1 = LoggerFactory.getLogger(LogbackTest.class); Logger logger2 = LoggerFactory.getLogger("cn.zzs.logback.LogbackTest"); System.err.println(logger == logger2);// true } 这里补充一个问题,该 logger 对象以 cn.zzs.logback.LogbackTest 命名,和我们配置文件中定义的 root logger 并不是同一个,但是为什么这个 logger 对象却拥有 root logger 的行为?
这要得益于 logger 的继承关系,如下图:

如果我们未指定当前 logger 的日志等级,logback 会将其日志等级设置为最近父级的日志等级。另外,默认情况下,当前 logger 也会继承最近父级持有的 appender。
下面测试下以上特性,将配置文件进行如下修改:
system.err ${LOG_PATTERN} true ${LOG_HOME}/${APP_NAME}/file-${bySecond}.log true false ${LOG_PATTERN}
这里自定义了一个 logger,日志等级是 error,appender 为文件输出。运行测试方法:
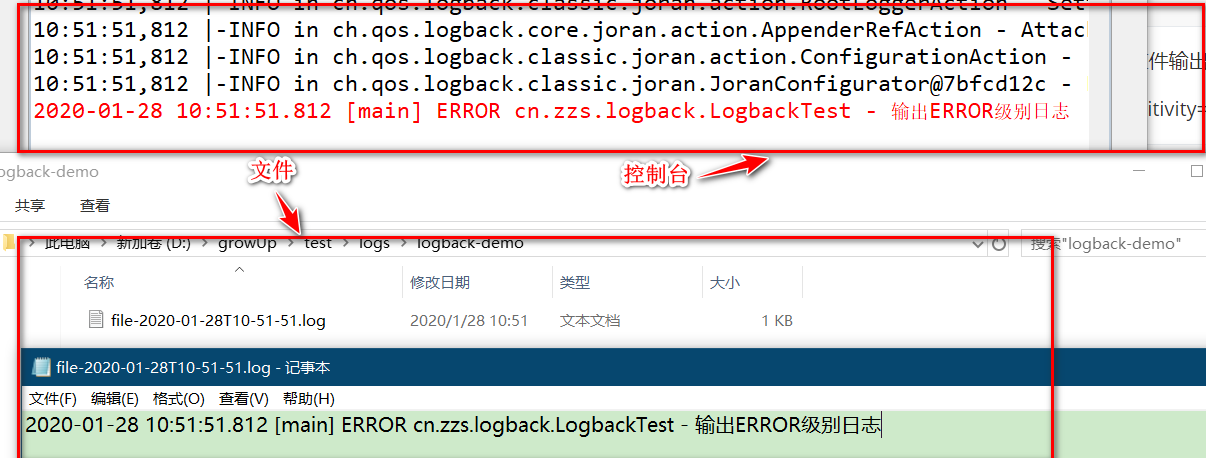
可以看到,名为 cn.zzs.logback.LogbackTest 的 logger 继承了名为 cn.zzs 的 logger 的日志等级和 appender,以及继承了 root logger 的 appender。
实际项目中,如果不希望继承父级的 appender,可以配置 additivity=“false” ,如下:
注意,因为以下配置都是建立在 logger 的继承关系上,所以这部分内容必须很好地理解。
appender
appender 用于定义日志的输出目的地和输出格式,被 logger 所持有。logback 为我们提供了以下几种常用的appender:
| 类名 | 描述 |
|---|---|
| ConsoleAppender | 将日志通过 System.out 或者 System.err 来进行输出,即输出到控制台。 |
| FileAppender | 将日志输出到文件中。 |
| RollingFileAppender | 继承自 FileAppender,也是将日志输出到文件,但文件具有轮转功能。 |
| DBAppender | 将日志输出到数据库 |
| SocketAppender | 将日志以明文方式输出到远程机器 |
| SSLSocketAppender | 将日志以加密方式输出到远程机器 |
| SMTPAppender | 将日志输出到邮件 |
本文仅会讲解前四种,后四种可参考。
ConsoleAppender
ConsoleAppender 支持将日志通过 System.out 或者 System.err 输出,即输出到控制台,常用属性如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| encoder | Encoder | 后面单独讲 |
| target | String | System.out 或 System.err。默认为 System.out |
| immediateFlush | boolean | 是否立即刷新。默认为 true。 |
| withJansi | boolean | 是否激活 Jansi 在 windows 使用 ANSI 彩色代码,默认值为 false。在windows电脑上我尝试开启这个属性并引入 jansi 包,但老是报错,暂时没有解决方案。 |
具体配置如下:
system.err %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n
FileAppender
FileAppender 支持将日志输出到文件中,常用属性如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| append | boolean | 是否追加写入。默认为 true |
| encoder | Encoder | 后面单独讲 |
| immediateFlush | boolean | 是否立即刷新。默认为 true。 |
| file | String | 要写入文件的路径。如果文件不存在,则新建。 |
| prudent | boolean | 是否采用安全方式写入,即使在不同的 JVM 或者不同的主机上运行 FileAppender 实例。默认的值为 false。 |
具体配置如下:
${LOG_HOME}/${APP_NAME}/file-${bySecond}.log ${LOG_PATTERN}
RollingFileAppender
RollingFileAppender 继承自 FileAppender,也是将日志输出到文件,但文件具有轮转功能。
RollingFileAppender 的属性如下所示:
| 属性名 | 类型 | 描述 |
|---|---|---|
| file | String | 要写入文件的路径。如果文件不存在,则新建。 |
| append | boolean | 是否追加写入。默认为 true。 |
| immediateFlush | boolean | 是否立即刷新。默认为true。 |
| encoder | Encoder | 后面单独将 |
| rollingPolicy | RollingPolicy | 定义文件如何轮转。 |
| triggeringPolicy | TriggeringPolicy | 定义什么时候发生轮转行为。如果 rollingPolicy 使用的类已经实现了 triggeringPolicy 接口,则不需要再配置 triggeringPolicy,例如 SizeAndTimeBasedRollingPolicy。 |
| prudent | boolean | 是否采用安全方式写入,即使在不同的 JVM 或者不同的主机上运行 FileAppender 实例。默认的值为 false。 |
具体配置如下:
${LOG_HOME}/${APP_NAME}/log-%d{yyyy-MM-dd}-%i.log 30 30GB 100MB ${LOG_PATTERN}
DBAppender
参见使用例子。
encoder
encoder 负责将日志事件按照配置的格式转换为字节数组,常用属性如下:
| 属性名 | 类型 | 描述 |
|---|---|---|
| pattern | String | 日志打印格式。 |
| outputPatternAsHeader | boolean | 是否将 pattern 字符串插入到日志文件顶部。默认false。 |
针对 pattern 属性,这里补充下它的常用转换字符:
| 转换字符 | 描述 |
|---|---|
| c{ length}lo{ length}logger{ length} | 输出 logger 的名字。可以通过 length 缩短其长度。但是,logger 名字最右边永远都会存在。例如,当我们设置 logger{0}时,cn.zzs.logback.LogbackTest 中的 LogbackTest 永远不会被删除 |
| C{ length}class{ length} | 输出发出日志请求的类的全限定名称。可以通过 length 缩短其长度。 |
| d{ pattern}date{ pattern} d{ pattern, timezone} date{ pattern, timezone} | 输出日志事件的日期。可以通过 pattern 设置日期格式,timezone 设置时区。 |
| m / msg / message | 输出与日志事件相关联的,由应用程序提供的日志信息。 |
| M / method | 输出发出日志请求的方法名。 |
| p / le / level | 输出日志事件的级别。 |
| t / thread | 输出生成日志事件的线程名。 |
| n | 输出平台所依赖的行分割字符。 |
| F / file | 输出发出日志请求的 Java 源文件名。 |
| caller{depth}caller{depthStart…depthEnd}caller{depth, evaluator-1, … evaluator-n}caller{depthStart…depthEnd, evaluator-1, … evaluator-n} | 输出生成日志的调用者所在的位置信息。 |
| L / line | 输出发出日志请求所在的行号。 |
| property{key} | 输出属性 key 所对应的值。 |
注意,在拼接 pattren 时,应该考虑使用“有意义的”转换字符,避免产生不必要的性能开销。具体配置如下:
%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{50} - %msg%n true
其中, 转换说明符 %-5level 表示日志事件的级别的字符应该向左对齐,保持五个字符的宽度。
filter
appender 除了定义日志的输出目的地和输出格式,其实也可以对日志事件进行过滤输出,例如,仅输出包含指定字符的日志。而这个功能需配置 filter。
LevelFilter
LevelFilter 基于级别来过滤日志事件。修改配置文件如下:
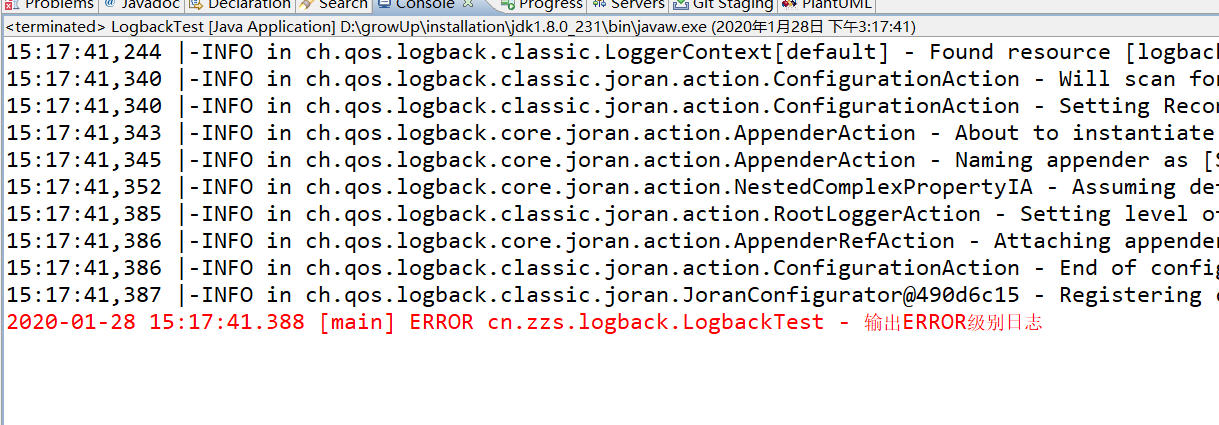
system.err ${LOG_PATTERN} ERROR ACCEPT DENY
运行测试方法,可见,虽然 root logger 的日志等级是 info,但最终只会打印 error 的日志:
ThresholdFilter
ThresholdFilter 基于给定的临界值来过滤事件。如果事件的级别等于或高于给定的临界,则过滤通过,否则会被拦截。配置如下:
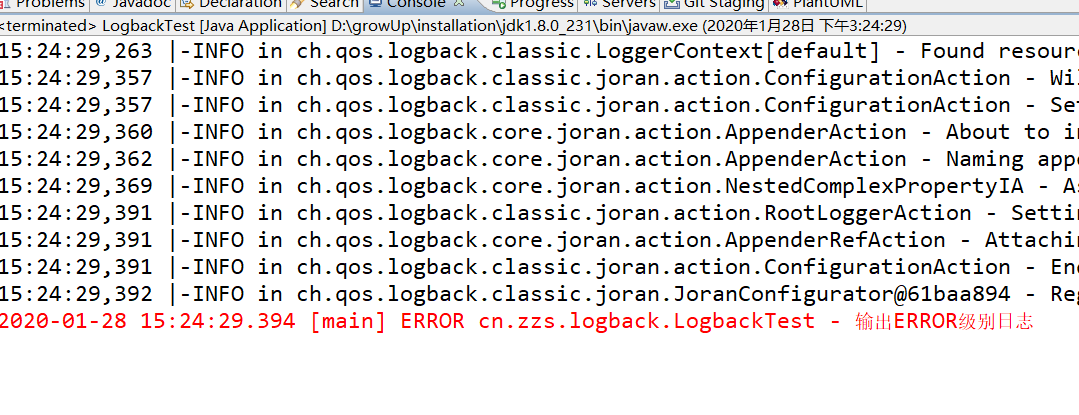
system.err ${LOG_PATTERN} ERROR
运行测试方法,可见,虽然 root logger 的日志等级是 info,但最终只会打印 error 的日志:
EvaluatorFilter
EvaluatorFilter 基于给定的标准来过滤事件。 它采用 Groovy 表达式作为评估的标准。配置如下:
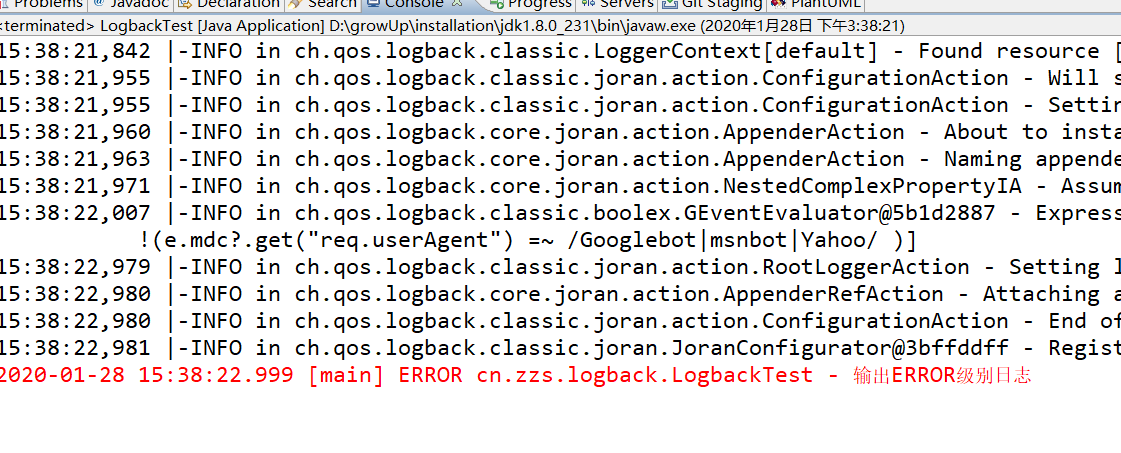
system.err ${LOG_PATTERN} e.level.toInt() >= ERROR.toInt() && !(e.mdc?.get("req.userAgent") =~ /Googlebot|msnbot|Yahoo/ ) DENY NEUTRAL
上面的过滤器引用自官网,规则为:让级别在 ERROR 及以上的日志事件在控制台显示,除非是由于来自 Google,MSN,Yahoo 的网络爬虫导致的错误。
注意,使用 GEventEvaluator 必须引入 groovy 的 jar 包:
org.codehaus.groovy groovy 3.0.0-rc-3
运行测试方法,输出如下结果:
EvaluatorFilter 除了支持 Groovy 表达式,还支持使用 java 代码来作为过滤标准,修改配置文件如下:
system.err ${LOG_PATTERN} return message.contains("ERROR"); DENY NEUTRAL
注意,使用 JaninoEventEvaluator 必须导入 janino 包,如下:
org.codehaus.janino janino 3.1.0
运行测试方法,输出如下结果:
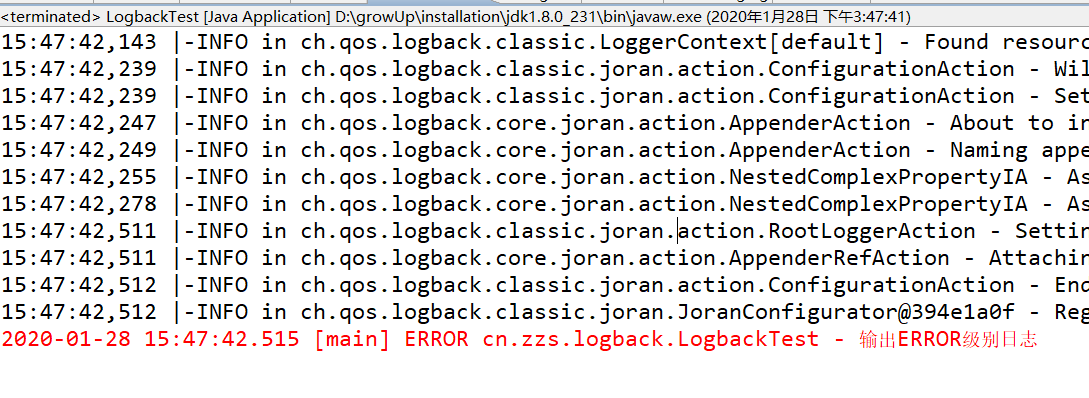
源码分析
logback 非常庞大、复杂,如果要将 logback 所有模块分析完,估计要花相当长的时间,所以,本文还是和以前一样,仅针对核心代码进行分析,当分析的方法存在多个实现时,也只会挑选其中一个进行讲解。文中没有涉及到的部分,感兴趣的可以自行研究。
接下来通过解决以下几个问题来逐步分析 logback 的源码:
- slf4j 是如何实现门面模式的?
- logback 如何加载配置?
- 获取我们所需的 logger?
- 如何将日志打印到控制台?
slf4j是如何实现门面模式的
slf4j 使用的是门面模式,不管使用什么日志实现,项目代码都只会用到 slf4j-api 中的接口,而不会使用到具体的日志实现的代码。slf4j 到底是如何实现门面模式的?接下来进行源码分析:
在我们的应用中,一般会通过以下方式获取 Logger 对象,我们就从这个方法开始分析吧:
Logger logger = LoggerFactory.getLogger(LogbackTest.class);
进入到 LoggerFactory.getLogger(Class<?> clazz)方法,如下。在调用这个方法时,我们一般会以当前类的 Class 对象作为入参。当然,logback 也允许你使用其他类的 Class 对象作为入参,但是,这样做可能不利于对 logger 的管理。通过设置系统属性-Dslf4j.detectLoggerNameMismatch=true,当实际开发中出现该类问题,会在控制台打印提醒信息。
public static Logger getLogger(Class clazz) { // 获取Logger对象,后面继续展开 Logger logger = getLogger(clazz.getName()); // 如果系统属性-Dslf4j.detectLoggerNameMismatch=true,则会检查传入的logger name是不是CallingClass的全限定类名,如果不匹配,会在控制台打印提醒 if (DETECT_LOGGER_NAME_MISMATCH) { Class autoComputedCallingClass = Util.getCallingClass(); if (autoComputedCallingClass != null && nonMatchingClasses(clazz, autoComputedCallingClass)) { Util.report(String.format("Detected logger name mismatch. Given name: \"%s\"; computed name: \"%s\".", logger.getName(), autoComputedCallingClass.getName())); Util.report("See " + LOGGER_NAME_MISMATCH_URL + " for an explanation"); } } return logger; } 进入到LoggerFactory.getLogger(String name)方法,如下。在这个方法中,不同的日志实现会返回不同的ILoggerFactory实现类:
public static Logger getLogger(String name) { // 获取工厂对象,后面继续展开 ILoggerFactory iLoggerFactory = getILoggerFactory(); // 利用工厂对象获取Logger对象 return iLoggerFactory.getLogger(name); } 进入到getILoggerFactory()方法,如下。INITIALIZATION_STATE代表了初始化状态,该方法会根据初始化状态的不同而返回不同的结果。
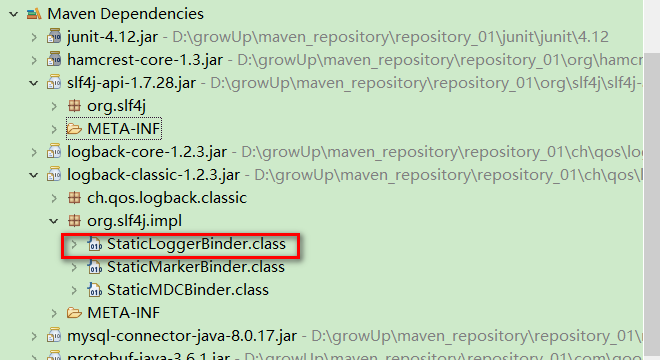
static final SubstituteLoggerFactory SUBST_FACTORY = new SubstituteLoggerFactory(); static final NOPLoggerFactory NOP_FALLBACK_FACTORY = new NOPLoggerFactory(); public static ILoggerFactory getILoggerFactory() { // 如果未初始化 if (INITIALIZATION_STATE == UNINITIALIZED) { synchronized (LoggerFactory.class) { if (INITIALIZATION_STATE == UNINITIALIZED) { // 修改状态为正在初始化 INITIALIZATION_STATE = ONGOING_INITIALIZATION; // 执行初始化 performInitialization(); } } } switch (INITIALIZATION_STATE) { // 如果StaticLoggerBinder类存在,则通过StaticLoggerBinder获取ILoggerFactory的实现类 case SUCCESSFUL_INITIALIZATION: return StaticLoggerBinder.getSingleton().getLoggerFactory(); // 如果StaticLoggerBinder类不存在,则返回NOPLoggerFactory对象 // 通过NOPLoggerFactory获取到的NOPLogger没什么用,它的方法几乎都是空实现 case NOP_FALLBACK_INITIALIZATION: return NOP_FALLBACK_FACTORY; // 如果初始化失败,则抛出异常 case FAILED_INITIALIZATION: throw new IllegalStateException(UNSUCCESSFUL_INIT_MSG); // 如果正在初始化,则SubstituteLoggerFactory对象,这个对象不作扩展 case ONGOING_INITIALIZATION: return SUBST_FACTORY; } throw new IllegalStateException("Unreachable code"); } 以上方法需要重点关注 StaticLoggerBinder这个类,它并不在 slf4j-api 中,而是在 logback-classic 中,如下图所示。其实分析到这里应该可以理解:slf4j 通过 StaticLoggerBinder 类与具体日志实现进行关联,从而实现门面模式。
接下来再简单看下LoggerFactory.performInitialization(),如下。这里会执行初始化,所谓的初始化就是查找 StaticLoggerBinder 这个类是不是存在,如果存在会将该类绑定到当前应用,同时,根据不同情况修改INITIALIZATION_STATE。代码比较多,我概括下执行的步骤:
- 如果 StaticLoggerBinder 存在且唯一,修改初始化状态为 SUCCESSFUL_INITIALIZATION;
- 如果 StaticLoggerBinder 存在但为多个,由 JVM 决定绑定哪个 StaticLoggerBinder,修改初始化状态为 SUCCESSFUL_INITIALIZATION,同时,会在控制台打印存在哪几个 StaticLoggerBinder,并提醒用户最终选择了哪一个 ;
- 如果 StaticLoggerBinder 不存在,打印提醒,并修改初始化状态为 NOP_FALLBACK_INITIALIZATION;
- 如果 StaticLoggerBinder 存在但 getSingleton() 方法不存在,打印提醒,并修改初始化状态为 FAILED_INITIALIZATION;
private final static void performInitialization() { // 查找StaticLoggerBinder这个类是不是存在,如果存在会将该类绑定到当前应用 bind(); // 如果检测存在 if (INITIALIZATION_STATE == SUCCESSFUL_INITIALIZATION) { // 判断StaticLoggerBinder与当前使用的slf4j是否适配 versionSanityCheck(); } } private final static void bind() { try { // 使用类加载器在classpath下查找StaticLoggerBinder类。如果存在多个StaticLoggerBinder类,这时会在控制台提醒并列出所有路径(例如同时引入了logback和slf4j-log4j12 的包,就会出现两个StaticLoggerBinder类) Set staticLoggerBinderPathSet = null; if (!isAndroid()) { staticLoggerBinderPathSet = findPossibleStaticLoggerBinderPathSet(); reportMultipleBindingAmbiguity(staticLoggerBinderPathSet); } // 这一步只是简单调用方法,但是非常重要。 // 可以检测StaticLoggerBinder类和它的getSingleton方法是否存在,如果不存在,分别会抛出 NoClassDefFoundError错误和NoSuchMethodError错误 // 注意,当存在多个StaticLoggerBinder时,应用不会停止,由JVM随机选择一个。 StaticLoggerBinder.getSingleton(); // 修改状态为初始化成功 INITIALIZATION_STATE = SUCCESSFUL_INITIALIZATION; // 如果存在多个StaticLoggerBinder,会在控制台提醒用户实际选择的是哪一个 reportActualBinding(staticLoggerBinderPathSet); // 对SubstituteLoggerFactory的操作,不作扩展 fixSubstituteLoggers(); replayEvents(); SUBST_FACTORY.clear(); } catch (NoClassDefFoundError ncde) { // 当StaticLoggerBinder不存在时,会将状态修改为NOP_FALLBACK_INITIALIZATION,并抛出信息 String msg = ncde.getMessage(); if (messageContainsOrgSlf4jImplStaticLoggerBinder(msg)) { INITIALIZATION_STATE = NOP_FALLBACK_INITIALIZATION; Util.report("Failed to load class \"org.slf4j.impl.StaticLoggerBinder\"."); Util.report("Defaulting to no-operation (NOP) logger implementation"); Util.report("See " + NO_STATICLOGGERBINDER_URL + " for further details."); } else { failedBinding(ncde); throw ncde; } } catch (java.lang.NoSuchMethodError nsme) { // 当StaticLoggerBinder.getSingleton()方法不存在时,会将状态修改为初始化失败,并抛出信息 String msg = nsme.getMessage(); if (msg != null && msg.contains("org.slf4j.impl.StaticLoggerBinder.getSingleton()")) { INITIALIZATION_STATE = FAILED_INITIALIZATION; Util.report("slf4j-api 1.6.x (or later) is incompatible with this binding."); Util.report("Your binding is version 1.5.5 or earlier."); Util.report("Upgrade your binding to version 1.6.x."); } throw nsme; } catch (Exception e) { failedBinding(e); throw new IllegalStateException("Unexpected initialization failure", e); } } 这里再补充一个问题,slf4j-api 中不包含 StaticLoggerBinder 类,为什么能编译通过呢?其实我们项目中用到的 slf4j-api 是已经编译好的 class 文件,所以不需要再次编译。但是,编译前 slf4j-api 中是包含 StaticLoggerBinder.java 的,且编译后也存在 StaticLoggerBinder.class ,只是这个文件被手动删除了。
logback如何加载配置
前面说过,logback 支持采用 xml、grovy 和 SPI 的方式配置文件,本文只分析 xml 文件配置的方式。
logback 依赖于 Joran(一个成熟的,灵活的并且强大的配置框架 ),本质上是采用 SAX 方式解析 XML。因为 SAX 不是本文的重点内容,所以这里不会去讲解相关的原理,但是,这部分的分析需要具备 SAX 的基础,可以参考我的另一篇博客:
logback 加载配置的代码还是比较繁琐,且代码量较大,这里就不一个个方法地分析了,而是采用类图的方式来讲解。下面是 logback 加载配置的大致图解:
这里再补充下图中几个类的作用:
| 类名 | 描述 |
|---|---|
| SaxEventRecorder | SaxEvent 记录器。继承了 DefaultHandler,所以在解析 xml 时会触发对应的方法,这些方法将触发的参数封装到 saxEven 中并放入 saxEventList 中 |
| SaxEvent | SAX 事件体。用于封装 xml 事件的参数。 |
| Action | 执行的配置动作。 |
| ElementSelector | 节点模式匹配器。 |
| RuleStore | 用于存放模式匹配器-动作的键值对。 |
结合上图,我简单概括下整个执行过程:
- 使用 SAX 方式解析 XML,解析过程中根据当前的元素类型,调用 DefaultHandler 实现类的方法,构造 SaxEvent 并将其放入集合 saxEventList 中;
- 当 XML 解析完成,会调用 EventPlayer 的方法,遍历集合 saxEventList 的 SaxEvent 对象,当该对象能够匹配到对应的规则,则会执行相应的 Action。
简单看下LoggerContext
现在回到 StaticLoggerBinder.getLoggerFactory()方法,如下。这个方法返回的 ILoggerFactory 其实就是 LoggerContext。
private LoggerContext defaultLoggerContext = new LoggerContext(); public ILoggerFactory getLoggerFactory() { // 如果初始化未完成,直接返回defaultLoggerContext if (!initialized) { return defaultLoggerContext; } if (contextSelectorBinder.getContextSelector() == null) { throw new IllegalStateException("contextSelector cannot be null. See also " + NULL_CS_URL); } // 如果是DefaultContextSelector,返回的还是defaultLoggerContext // 如果是ContextJNDISelector,则可能为不同线程提供不同的LoggerContext 对象 // 主要取决于是否设置系统属性-Dlogback.ContextSelector=JNDI return contextSelectorBinder.getContextSelector().getLoggerContext(); } 下面简单看下 LoggerContext 的 UML 图。它不仅作为获取 logger 的工厂,还绑定了一些全局的 Object、property 和 LifeCycle。
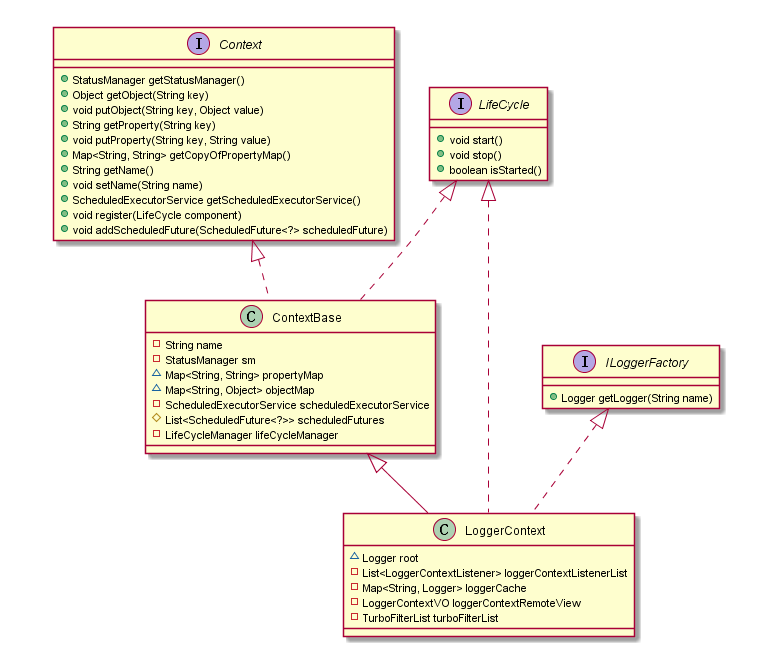
获取logger对象
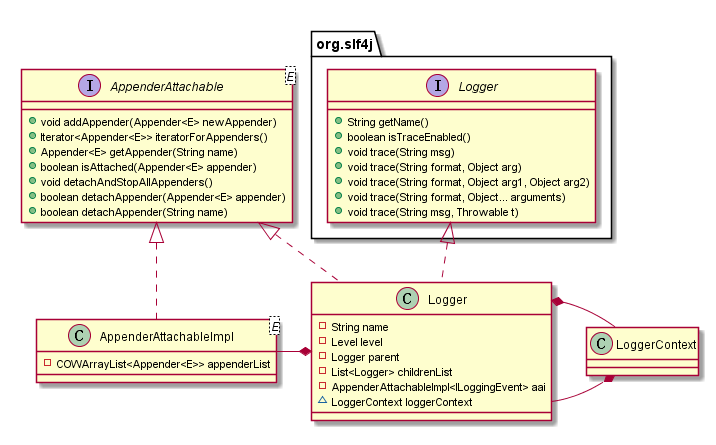
这里先看下 Logger 的 UML 图,如下。在 Logger 对象中,持有了父级 logger、子级 logger 和 appender 的引用。
进入LoggerContext.getLogger(String)方法,如下。这个方法逻辑简单,但是设计非常巧妙,可以好好琢磨下。我概括下主要的步骤:
- 如果获取的是 root logger,直接返回;
- 如果获取的是 loggerCache 中缓存的 logger,直接返回;
- 循环获取 logger name 中包含的所有 logger,如果不存在就创建并放入缓存;
- 返回 logger name 对应的 logger。
public final Logger getLogger(final String name) { if (name == null) { throw new IllegalArgumentException("name argument cannot be null"); } // 如果获取的是root logger,直接返回 if (Logger.ROOT_LOGGER_NAME.equalsIgnoreCase(name)) { return root; } int i = 0; Logger logger = root; // 在loggerCache中缓存着已经创建的logger,如果存在,直接返回 Logger childLogger = (Logger) loggerCache.get(name); if (childLogger != null) { return childLogger; } // 如果还找不到,就需要创建 // 注意,要获取以cn.zzs.logback.LogbackTest为名的logger,名为cn、cn.zzs、cn.zzs.logback的logger不存在的话也会被创建 String childName; while (true) { // 从起始位置i开始,获取“.”的位置 int h = LoggerNameUtil.getSeparatorIndexOf(name, i); // 截取logger的名字 if (h == -1) { childName = name; } else { childName = name.substring(0, h); } // 修改起始位置,以获取下一个“.”的位置 i = h + 1; synchronized (logger) { // 判断当前logger是否存在以childName命名的子级 childLogger = logger.getChildByName(childName); if (childLogger == null) { // 通过当前logger来创建以childName命名的子级 childLogger = logger.createChildByName(childName); // 放入缓存 loggerCache.put(childName, childLogger); // logger总数量+1 incSize(); } } // 当前logger修改为子级logger logger = childLogger; // 如果当前logger是最后一个,则跳出循环 if (h == -1) { return childLogger; } } } 进入Logger.createChildByName(String)方法,如下。
Logger createChildByName(final String childName) { // 判断要创建的logger在名字上是不是与当前logger为父子,如果不是会抛出异常 int i_index = LoggerNameUtil.getSeparatorIndexOf(childName, this.name.length() + 1); if (i_index != -1) { throw new IllegalArgumentException("For logger [" + this.name + "] child name [" + childName + " passed as parameter, may not include '.' after index" + (this.name.length() + 1)); } // 创建子logger集合 if (childrenList == null) { childrenList = new CopyOnWriteArrayList (); } Logger childLogger; // 创建新的logger childLogger = new Logger(childName, this, this.loggerContext); // 将logger放入集合中 childrenList.add(childLogger); // 设置有效日志等级 childLogger.effectiveLevelInt = this.effectiveLevelInt; return childLogger; } logback 在类的设计上非常值得学习, 使得许多代码逻辑也非常简单易懂。
打印日志到控制台
这里以Logger.debug(String)为例,如下。这里需要注意 TurboFilter 和 Filter 的区别,前者是全局的,每次发起日志记录请求都会被调用,且在日志事件创建前调用,而后者是附加的,作用范围较小。因为实际项目中 TurboFilter 使用较少,这里不做扩展,感兴趣可参考。
public static final String FQCN = ch.qos.logback.classic.Logger.class.getName(); public void debug(String msg) { filterAndLog_0_Or3Plus(FQCN, null, Level.DEBUG, msg, null, null); } private void filterAndLog_0_Or3Plus(final String localFQCN, final Marker marker, final Level level, final String msg, final Object[] params, final Throwable t) { // 使用TurboFilter过滤当前日志,判断是否通过 final FilterReply decision = loggerContext.getTurboFilterChainDecision_0_3OrMore(marker, this, level, msg, params, t); // 返回NEUTRAL表示没有TurboFilter,即无需过滤 if (decision == FilterReply.NEUTRAL) { // 如果需要打印日志的等级小于有效日志等级,则直接返回 if (effectiveLevelInt > level.levelInt) { return; } } else if (decision == FilterReply.DENY) { // 如果不通过,则不打印日志,直接返回 return; } // 创建LoggingEvent buildLoggingEventAndAppend(localFQCN, marker, level, msg, params, t); } 进入Logger.buildLoggingEventAndAppend(String, Marker, Level, String, Object[], Throwable),如下。 logback 中,日志记录请求会被构造成日志事件 LoggingEvent,传递给对应的 appender 处理。
private void buildLoggingEventAndAppend(final String localFQCN, final Marker marker, final Level level, final String msg, final Object[] params, final Throwable t) { // 构造日志事件LoggingEvent LoggingEvent le = new LoggingEvent(localFQCN, this, level, msg, t, params); // 设置标记 le.setMarker(marker); // 通知LoggingEvent给当前logger持有的和继承的appender callAppenders(le); } 进入到Logger.callAppenders(ILoggingEvent),如下。
public void callAppenders(ILoggingEvent event) { int writes = 0; // 通知LoggingEvent给当前logger的持有的和继承的appender处理日志事件 for (Logger l = this; l != null; l = l.parent) { writes += l.appendLoopOnAppenders(event); // 如果设置了logger的additivity=false,则不会继续查找父级的appender // 如果没有设置,则会一直查找到root logger if (!l.additive) { break; } } // 当前logger未设置appender,在控制台打印提醒 if (writes == 0) { loggerContext.noAppenderDefinedWarning(this); } } private int appendLoopOnAppenders(ILoggingEvent event) { if (aai != null) { // 调用AppenderAttachableImpl的方法处理日志事件 return aai.appendLoopOnAppenders(event); } else { // 如果当前logger没有appender,会返回0 return 0; } } 在继续分析前,先看下 Appender 的 UML 图(注意,Appender 还有很多实现类,这里只列出了常用的几种)。Appender 持有 Filter 和 Encoder 到引用,可以分别对日志进行过滤和格式转换。
本文仅涉及到 ConsoleAppender 的源码分析。
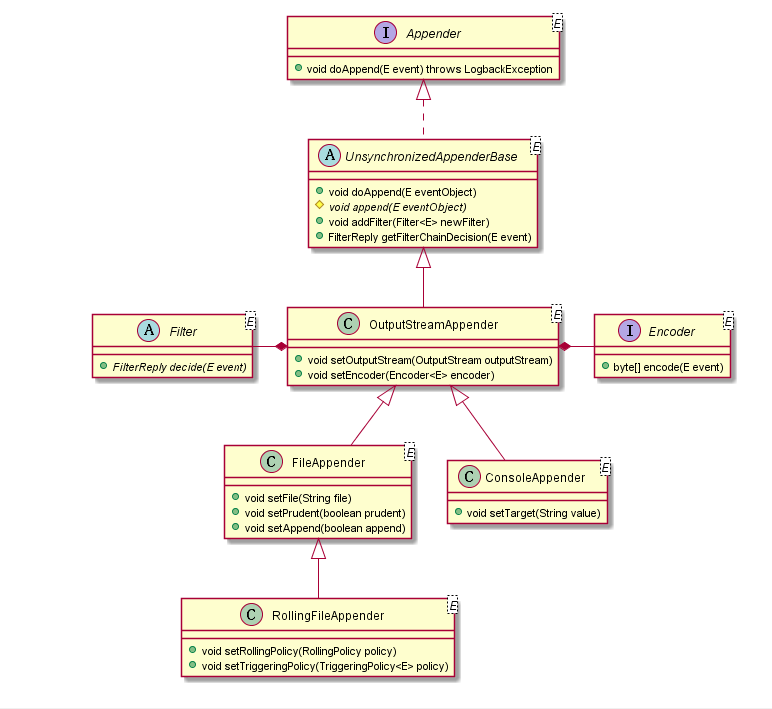
继续进入到AppenderAttachableImpl.appendLoopOnAppenders(E),如下。这里会遍历当前 logger 持有的 appender,并调用它们的 doAppend 方法。
public int appendLoopOnAppenders(E e) { int size = 0; // 获得当前logger的所有appender final Appender [] appenderArray = appenderList.asTypedArray(); final int len = appenderArray.length; for (int i = 0; i < len; i++) { // 调用appender的方法 appenderArray[i].doAppend(e); size++; } // 这个size为appender的数量 return size; } 为了简化分析,本文仅分析打印日志到控制台的过程,所以进入到UnsynchronizedAppenderBase.doAppend(E)方法,如下。
public void doAppend(E eventObject) { // 避免doAppend方法被重复调用?? // TODO 这一步不是很理解,同一个线程还能同时调用两次这个方法? if (Boolean.TRUE.equals(guard.get())) { return; } try { guard.set(Boolean.TRUE); // 过滤当前日志事件是否允许打印 if (getFilterChainDecision(eventObject) == FilterReply.DENY) { return; } // 调用实现类的方法 this.append(eventObject); } catch (Exception e) { if (exceptionCount++ < ALLOWED_REPEATS) { addError("Appender [" + name + "] failed to append.", e); } } finally { guard.set(Boolean.FALSE); } } 进入到OutputStreamAppender.append(E),如下。
protected void append(E eventObject) { // 如果appender未启动,则直接返回,不处理日志事件 if (!isStarted()) { return; } subAppend(eventObject); } protected void subAppend(E event) { // 这里又判断一次?? if (!isStarted()) { return; } try { // 这一步不是很懂 TODO if (event instanceof DeferredProcessingAware) { ((DeferredProcessingAware) event).prepareForDeferredProcessing(); } // 调用encoder的方法将日志事件转化为字节数组 byte[] byteArray = this.encoder.encode(event); // 打印日志 writeBytes(byteArray); } catch (IOException ioe) { this.started = false; addStatus(new ErrorStatus("IO failure in appender", this, ioe)); } } 看下LayoutWrappingEncoder.encode(E),如下。
public byte[] encode(E event) { // 根据配置格式处理日志事件 String txt = layout.doLayout(event); // 将字符转化为字节数组并返回 return convertToBytes(txt); } 后面会调用PatternLayout.doLayout(ILoggingEvent)将日志的消息进行处理,这部分内容我就不继续扩展了,感兴趣可以自行研究。
以上是 logback 的源码基本分析完成,后续有空再作补充。
参考资料
相关源码请移步:https://github.com/ZhangZiSheng001/logback-demo
本文为原创文章,转载请附上原文出处链接: https://www.cnblogs.com/ZhangZiSheng001/p/12246122.html